- Подробности
- Категория: Проекты
- Просмотров: 558
Представляю c++ LibTorch имплементацию EfficientViT. Это визуальный трансформер, сконструированный из вычислительно-эффективных блоков, таких как линейное многомасштабное внимание и эффективные свертки с ядрами небольшого масштаба. Вот ссылка на оригинальный проект, а вот ссылка на статью.
Используется он в генеративной модели SANA, как бэкбон для детектирования с открытым словарем GroundingDINO, как часть модели из семейства Segment Anything: EfficientviT-SAM, для сжимающих автокодировщиков и много где еще. Я же надеюсь в будущем попробовать использовать EfficientViT чтобы построить NeRF в сжатом пространстве DC-AE(Deep Compression Autoencoder) и, возможно, поэкспериментировать с 3D Segment Anything и 3D генерацией. Пеимуществом данной модели помимо высокой вычислительной эффективности и точности является глобальное рецептивное поле.
Попутно было решено множество технических вопросов реализации конфигурируемых моделей на c++ с использованием библиотеки LibTorch, а также загрузки весов из формата .safetensors. Поэтому надеюсь что выложенный код окажется полезен. В репозитории реализован пример сжимающего автокодировщика и вот пример его работы:

- Подробности
- Категория: Проекты
- Просмотров: 1396
Немного программирования и любой человек даже не являясь специалистом в речевых технологиях может собрать себе голосового асистента работающего локально без интернета, без всяких подписок и рекламы. Общение голосом на руссском языке с прототипом, работающим локально у меня на ноутбуке. Использованы проекты llama.cpp, whisper.cpp от Georgi Gerganov, языковая модель Saiga 2 13b от Ильи Гусева.
- Подробности
- Категория: Проекты
- Просмотров: 1824
Возьмем следующие изображения:



и следующие текстовые метки:
{"кот", "медведь", "лиса"}
и посчитаем матрицу вероятностей соответствия этих изображений этим меткам используя самую большую модель на 475млн параметров!
#include "TorchHeader.h" #include <opencv2/imgproc/imgproc.hpp> #include <opencv2/imgproc/types_c.h> #include <opencv2/highgui/highgui.hpp> #include "RuCLIP.h" #include "RuCLIPProcessor.h" int main(int argc, const char* argv[]) { setlocale(LC_ALL, ""); const int INPUT_IMG_SIZE = 336; torch::manual_seed(24); torch::Device device(torch::kCPU); if (torch::cuda::is_available()) { std::cout << "CUDA is available! Running on GPU." << std::endl; device = torch::Device(torch::kCUDA); } else { std::cout << "CUDA is not available! Running on CPU." << std::endl; } CLIP clip = FromPretrained("..//data//ruclip-vit-large-patch14-336"); clip->to(device); RuCLIPProcessor processor( "..//data//ruclip-vit-large-patch14-336//bpe.model", INPUT_IMG_SIZE, 77, { 0.48145466, 0.4578275, 0.40821073 }, { 0.26862954, 0.26130258, 0.27577711 } ); ////Или можно без него сначала попробовать //RuCLIPPredictor(clip, processor, device, templates, 8); //Загрузить картинки std::vector <cv::Mat> images; images.push_back(cv::imread("..//data//test_images//1.png", cv::ImreadModes::IMREAD_COLOR)); images.push_back(cv::imread("..//data//test_images//2.jpg", cv::ImreadModes::IMREAD_COLOR)); images.push_back(cv::imread("..//data//test_images//3.jpg", cv::ImreadModes::IMREAD_COLOR)); //resize->[336, 336] for (auto &it : images) cv::resize(it, it, cv::Size(INPUT_IMG_SIZE, INPUT_IMG_SIZE)); //Завести метки std::vector<std::string> labels; labels = {"кот", "медведь", "лиса"}; auto dummy_input = processor(labels, images); try { torch::Tensor logits_per_image = clip->forward(dummy_input.first.to(device), dummy_input.second.to(device)); torch::Tensor logits_per_text = logits_per_image.t(); auto probs = logits_per_image.softmax(/*dim = */-1).detach().cpu(); std::cout << "probs per image: " << probs << std::endl; } catch (std::exception& e) { std::cout << e.what() << std::endl; } }
Получим следующий вывод:
0.8879 0.0063 0.1058
0.0014 0.0026 0.9960
0.0002 0.9994 0.0003
Очевидно, шалость удалась!
Вот ссылка на репозиторий с проектом: https://github.com/DeliriumV01D/RuCLIP
- Подробности
- Категория: Проекты
- Просмотров: 1755

NeRF - это метод аппроксимации объемной сцены нейросетью по серии изображений с известными положениями камер и рендеринга этой сцены. Вот ссылка на ригинальную статью: https://arxiv.org/pdf/2003.08934.pdf
Весь код доступен в репозитории: https://github.com/DeliriumV01D/NeRFpp
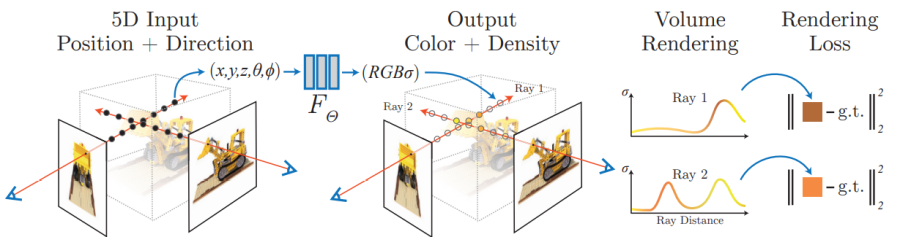
Вся "физика" сводится к формуле объемного рендеринга:
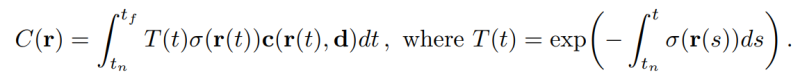
Здесь C - результирующий цвет луча, T - коэффицицент пропускания, c - локальный цвет, σ - его плотность, r - коордната на луче, а d - направление.
NERF кодирует непрерывную объемную функцию что дает хорошее качество и требует мало места для хранения
5D(x,y,z,theta,phi) -> 3D(r,g,b)
8 слоев по 256 нейронов с активациями ReLU формируют фичер вектор к которому конкатенируется направление камеры и подается на оставшиеся 256-128-3
Что можно делать с помощью NeRF? NeRF - это избавление от шумов за счет статистичекого "усреднения", замена плотному стерео, рендеринг сцены из новых позиций, ускорение отрисовки сложных сцен, сжатое представление, простое извлечение формы, замена освещения и материалов, аугментация(из всех промежуточных положений)
подготовка локаций для AR, создание аватара, объединение с 3D печатью/строительством/позиционированием - построение NeRF проекции. Объединив NeRF с генеративной моделью можно выглючивать объемные сцены из единственного либо нескольких плоских изображений.
В текущей реализации имеется:
Модуль обучения нейросети, реализация метода forward и регистрация сабмодулей, инициализация и хранение весов, чтение входных данных в формате blender, модуль позиционного кодирования для NeRF, цикл обучения и инференс, объемный рендеринг, батчификация, грубая и точная сети и иерархическое семплирование. c++ и libTorch все как мы любим. Есть также зависимости от библиотек OpenCV и nlohman json. Референсная реализация на PyTorch: https://github.com/yenchenlin/nerf-pytorch
Дополнение:
Добавлена реализация HashNeRF - быстрый в обучении NeRF который представляет из себя большую обучаемую хэш-таблицу (HashEmbedder) поверх которой работает очень маленькая моделька для цветовой плотности. Также используется энкодер на сферических гармониках для зависимости от угла обзора. Придумали HashNeRF и очень эффективно реализовали в nvidia: Instant Neural Graphics Primitives with a Multiresolution Hash Encoding: https://nvlabs.github.io/instant-ngp/ . Моя реализация, к сожалению, сильно проигрывает. Я использовал как референс следующую реализацию на PyTorch: https://github.com/yashbhalgat/HashNeRF-pytorch.
- Подробности
- Категория: Проекты
- Просмотров: 1578
Выложил https://github.com/DeliriumV01D/TransGANpp игрушечный пример обучения целиком трансформерной GAN на данных MNIST dataset. Имеется train loop для генератора и дискриминатора. Именование модулей чтобы потом при инициализации весов различать их по типу. Добавлена OpenCV визуализация выхода сети - для этого делается конвертация torch::Tensor -> cv::Mat. Подсчет количества весов (чтоб было меньше чем для DCGAN выполняющего эту же задачу).
Используется классический необучаемый позиционный энкодер собственной реализации. Инициализация весов трансформеров в данную секунду осуществляется методом xavier_normal. Для стабилизации обучения в случае если генератор побеждает, то пропускаем апдейт генератора, пока дискриминатор не вернет лидерство. Имеется управление скоростью обучения. Переход от изображения к последовательности токенов осуществляется посредством n сверток 16 на 16 со страйдом на размер свертки и паддингом 6. Из изображения 28 на 28 получается n изображений 2 на 2. Из которых, в свою очередь, собирается 4 токена длины n. Число блоков трансформеров взято равное 3. Количество голов механизма внимания - 4. Метод оптимизации - adam(0.5, 0,9).
- Вы здесь:
-
Главная

- Проекты